CAMOMILE
Collaborative Annotation of multi-Modal, MultI-Lingual and multi-mEdia documents
Past project
Inspiration
Human activity is constantly generating large volumes of heterogeneous multimedia data, in particular on the internet. To be interpreted and reused in various kinds of applications, these data should be annotated, and available in very large amounts. However, annotating data requires a great deal of work, which is currently only imperfectly or partially automated. The Camomile project aims at developing the first prototype of a collaborative annotation framework for 3M (multi-modal, multi-lingual and multi-media) data, in which the manual annotation will be done remotely across a network of computers, while the final annotation will be localised on a main server.
Innovation
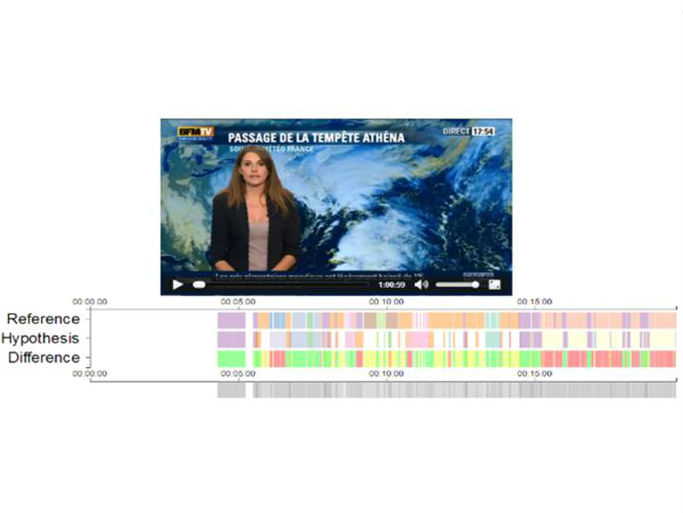
In order to develop this new annotation concept, we focus on the problem of person annotation (Who is speaking? Who can be seen?) in video, which requires collaboration between high level automatic systems dealing with different media (video, speech, audio tracks, optical character recognition (OCR), etc.) The quality of the annotations will be evaluated through several use cases, such as person retrieval, on different corpora. Thanks to its expertise in knowledge extraction and visualisation, the Luxembourg Institute of Science and Technology is responsible for the design and development of a visual platform to support the collaborative annotation.
Impact
This new way of envisioning the annotation process has already led to methodologies, tools, instruments and data that are useful for the whole scientific community with an interest in 3M annotated data. The collaborative visual platform produced within the project, open sourced to the public, is constantly being enriched and tested, with the latest evaluation carried out at Grenoble University in 2015. It has also been demonstrated at several events, including the international Errare 2013 Workshop.
![]()
Research domains
- Environment
Share this page:





Project Factsheet
Partners
Financial Support
Contact

Further information
Official project website: github.com/camomile-project